China’s technology company DeepSeek announced its v3 model, which the editor thinks is the biggest surprise of the open-source AI model this year. However, someone found that the model calls itself “ChatGPT” when answering, so it is jokingly called a copycat work. As a Hong Kong technology media, we believe it is better to delve into why this AI can shock the industry rather than just laughing at it. This is not the traditional “ignorance of intellectual property rights, low cost copying, and mass production” Taobao product model, but a possible breakthrough in AI technology that may rewrite market rules.
What is DeepSeek?
DeepSeek is an artificial intelligence company founded by the Chinese private equity firm “Huanfang Quantitative” in 2023, focusing on the development of advanced AI technology. Although it has been established for a short time, DeepSeek has quickly become a focus in the AI field with its efficient technological innovation. Its latest achievement, the DeepSeek-V3 model, boasts up to 67.1 billion parameters, creating a new standard in terms of performance and cost balance.
The two key technologies behind low-cost
DeepSeek can develop a high-performance AI model within 2 years with only 5.57 million US dollars, forming a sharp contrast with the training cost of OpenAI’s GPT-4 model at 63 million US dollars, and even surpassing the budget of the future GPT-5, which may reach 500 million US dollars. These achievements are attributed to the following several innovative technologies:
Precision activation of the “Brain Cell” section
DeepSeek-V3 adopts a design called “Hybrid Expert Architecture,” which, simply put, only activates part of the “brain cells” when needed instead of all of them, thus greatly reducing the consumption of computing resources. Training the model only used 2048 NVIDIA H800 GPUs.
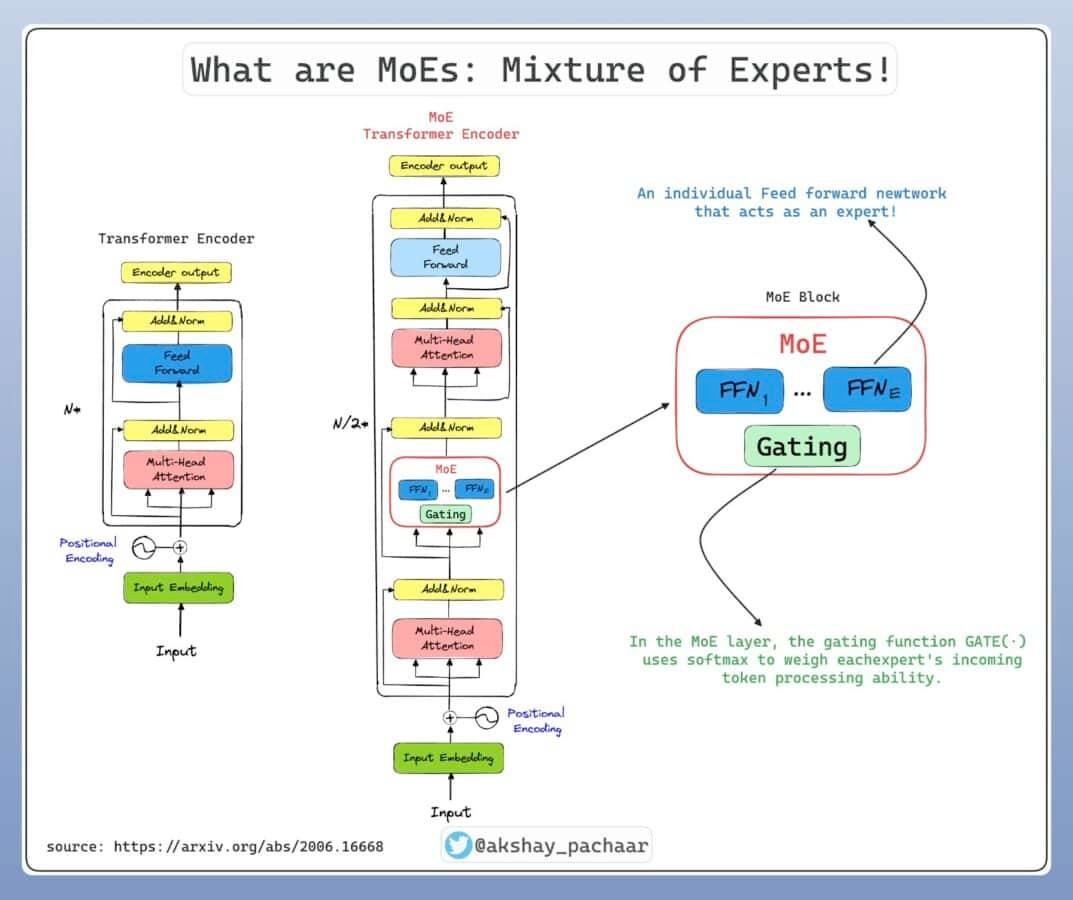
Data processing and energy-saving innovation
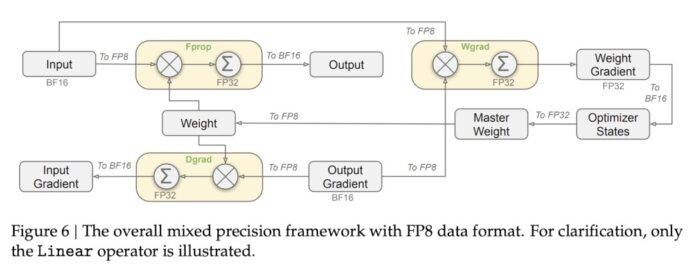
DeepSeek develops internal tools to generate high-quality training data and further compresses computational resources using “distillation technology.” During the training process, FP8 technology is adopted, which significantly reduces memory demand while improving efficiency. The use of FP8 reduces memory requirements to only half of traditional FP16 technology, while maintaining computational performance.
Mobile phones and tablets will have greater AI advantages
DeepSeek-V3’s design significantly reduces resource requirements during the inference process, thanks to its innovative “hybrid expert architecture.” This model only needs to activate 3.7 billion parameters for inference, instead of using the full model’s 67.1 billion parameters, thereby reducing the resource consumption of real-time computation. In contrast, complete models like GPT-4 typically require a large amount of computing power and memory resources during inference, and their operation may require hundreds of GB of memory support.
To further enhance performance, DeepSeek-V3 introduces Multi-Head Potential Attention (MLA) technology, which can significantly reduce memory requirements during long text processing, cutting resource consumption by up to 96%. At the same time, the addition of the RoPE (Relative Positional Encoding) also ensures that the compressed data can still accurately retain positional information, further improving inference speed and accuracy.
These breakthroughs show that future AI not only can run efficiently on high-end servers but can also be easily ported to consumer devices such as smartphones and tablets for operation, allowing users to enjoy AI functions comparable to traditional high-performance hardware at a low cost, bringing a truly democratized technological experience to the market.
The training model is being questioned
Although DeepSeek has shown great potential, it has also attracted some skepticism. For example, DeepSeek-V3 claimed to be ChatGPT during testing, causing outsiders to doubt whether the training data included content generated by ChatGPT. This has sparked discussions about the independence of the model and the transparency of the data. To date, DeepSeek has not made an official response, which also highlights the necessity of transparency and standardization in the development of AI technology. Sam from Open AI also seems to have made some “interesting” comments about this on X.
6 major reasons why technology giants are surprised
After exploring the technology behind Deepseek, we understand why it has caused a great stir in the industry:
Low cost and high efficiency
Deepseek’s development took only two months and about 5.5 million US dollars, significantly lower than the tens of billions of dollars required by giants like OpenAI and Google to develop models. This rapid and efficient development model shows that the barriers of existing large language models (LLM) are shrinking significantly.
Performance is not lagging behind
According to third-party testing standards, Deepseek’s performance is comparable to the most advanced models of OpenAI and Meta, and even better in some areas. This indicates that it is no longer necessary to invest a large amount of capital to train high-performance models.
Break hardware limitations
Deepseek uses the NVIDIA H800 chip for training, which is a version with lower performance than the H100 but easier to obtain. This method not only reduces hardware costs but also avoids supply restrictions on the H100.
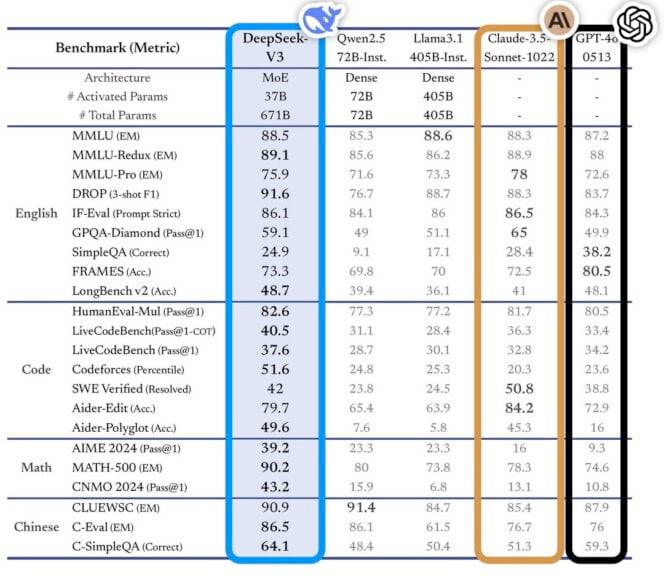
Summary: The path of AI development with Chinese characteristics
China’s market has the world’s largest data resources, but is constrained by multiple factors in terms of hardware computing power, such as technological blockade and hardware supply shortages, which makes Chinese AI companies pay more attention to efficiency optimization. The success of DeepSeek perfectly demonstrates a new balance point between resources and efficiency. At the same time, giants like Google, Microsoft, and Meta have already started to bet on nuclear energy to support future development due to the huge electricity consumption of AI training. In comparison, emerging companies like DeepSeek have obviously chosen a different path, reducing resource waste through technological innovation and providing new ideas for the entire industry. DeepSeek’s story tells us that the competition of AI in the future is not only about technology itself, but also about how to achieve the best results with limited resources. This model may be the key to changing the rules of the market game.
